Building a GPT from Scratch in JAX/Flax:
Building a GPT from Scratch in JAX/Flax
![]()
A honest account of building a transformer language model using JAX, Flax NNX, and the TinyStories dataset — including every wall I hit along the way.
Why JAX?
Most transformer tutorials start with PyTorch. It’s intuitive, well-documented, and the ecosystem is enormous. So why would anyone choose JAX for a from-scratch GPT implementation?
Three reasons:
1. XLA compilation. JAX compiles your code down to XLA (Accelerated Linear Algebra), which means the same code runs on CPU, GPU, and TPU without modification. You decorate a function with @jax.jit and JAX handles the rest.
2. Functional purity. JAX forces you to write pure functions — no hidden state, no in-place mutations. This is uncomfortable at first, but it makes your model logic explicit and easier to reason about.
3. vmap. JAX’s vmap lets you write code for a single example and automatically vectorize it across a batch. This isn’t just a convenience — it changes how you think about batching entirely.
That said, JAX has a steeper learning curve than PyTorch. This post is an honest account of what that looks like in practice.
The Architecture
The model is a decoder-only transformer — the same family as GPT — trained to predict the next token in a sequence. Here’s the full picture:
Input tokens (batch_size, seq_len)
↓
Token Embeddings + Positional Embeddings
↓
┌─────────────────────┐
│ Transformer Block │ × 6
│ ┌───────────────┐ │
│ │ Causal Multi- │ │
│ │ Head Attention│ │
│ └───────────────┘ │
│ ↓ │
│ Residual Add │
└─────────────────────┘
↓
Linear Projection → Logits (batch_size, seq_len, vocab_size)
Hyperparameters:
| Parameter | Value |
|---|---|
| Transformer blocks | 6 |
| Embedding dimension | 192 |
| Attention heads | 6 |
| Feed-forward dimension | 512 |
| Max sequence length | 128 |
| Vocabulary | GPT-2 tokenizer (50,257 tokens) |
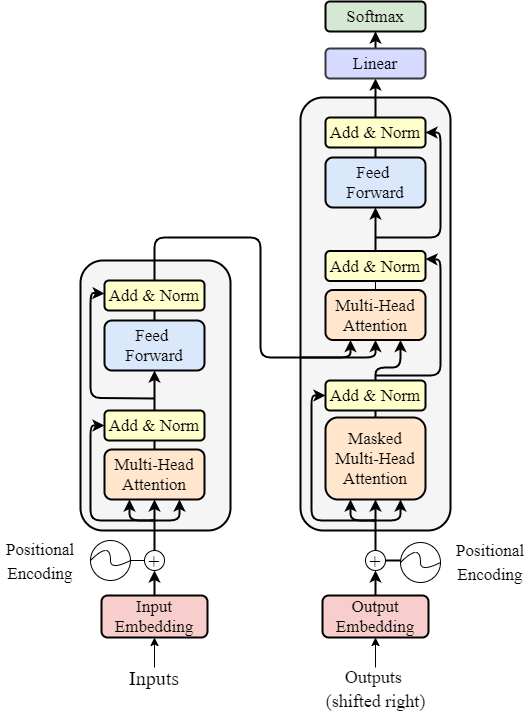
The transformer architecture — our model uses the decoder side (right) only.
Small by modern standards, but trainable on a single GPU and expressive enough to learn story structure.
Part 1: Embeddings
The first layer combines token embeddings (what is this word?) with positional embeddings (where is it in the sequence?):
class TokenAndPositionEmbedding(nnx.Module):
def __init__(self, maxlen, vocab_size, embed_dim, *, rngs):
self.token_emb = nnx.Embed(vocab_size, embed_dim, rngs=rngs)
self.pos_emb = nnx.Embed(maxlen, embed_dim, rngs=rngs)
def __call__(self, x):
seq_len = x.shape[1]
positions = jnp.arange(seq_len)[None, :] # shape: (1, seq_len)
return self.token_emb(x) + self.pos_emb(positions)
The key line is jnp.arange(seq_len)[None, :] — the [None, :] adds a batch dimension so positions broadcast correctly across the batch. This is a pattern used constantly in JAX.
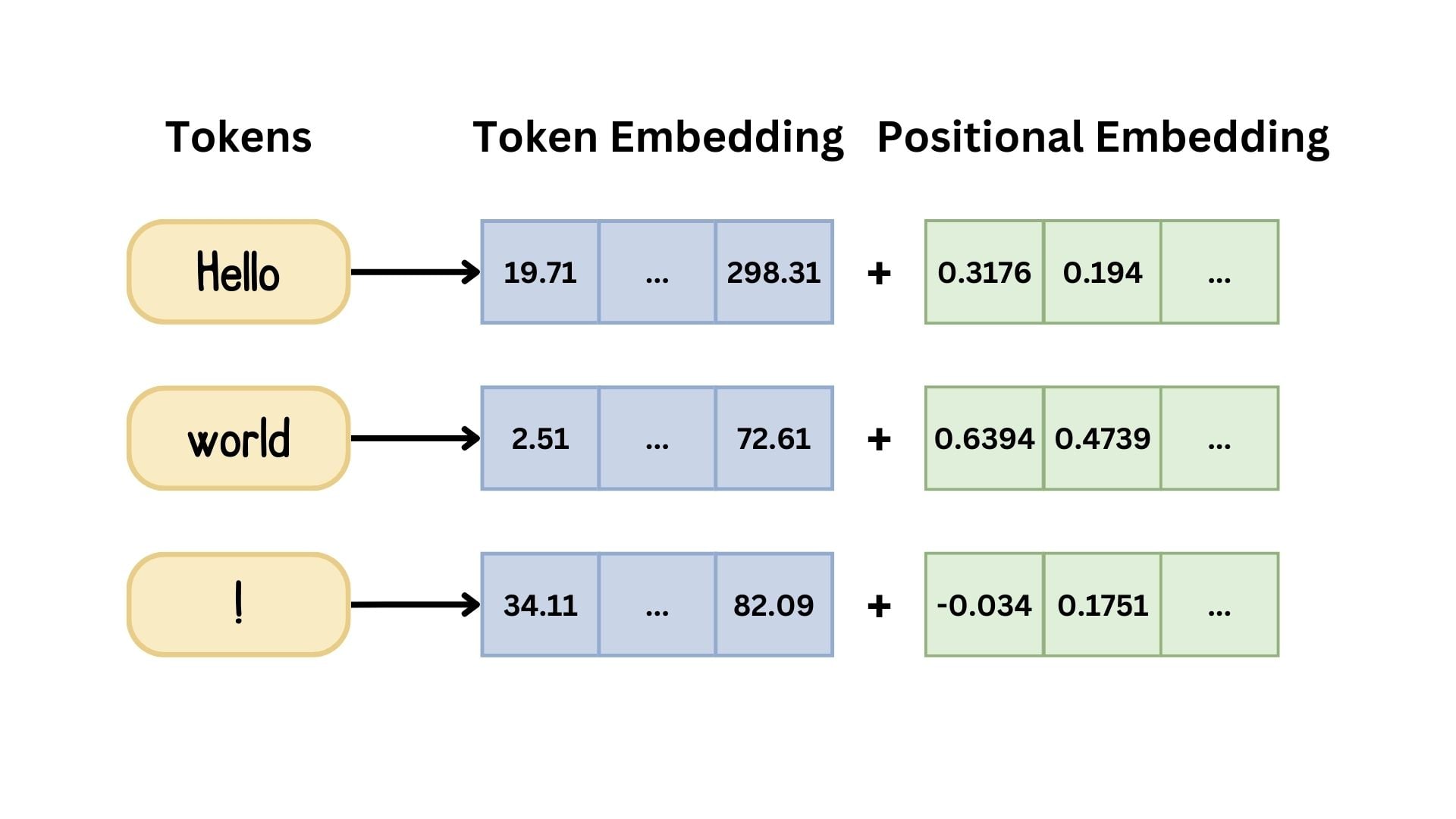
Token embeddings encode meaning; positional embeddings encode order. Both are summed before entering the transformer.
Part 2: Causal Attention
The attention block uses Flax NNX’s built-in MultiHeadAttention, but the critical piece is the causal mask — without it, the model can look into the future when predicting the next token, which is cheating.
class MiniGPT(nnx.Module):
def causal_attention_mask(self, seq_len):
# Lower triangular matrix — token i can only attend to tokens 0..i
return jnp.tril(jnp.ones((seq_len, seq_len)))
def __call__(self, token_ids):
seq_len = token_ids.shape[1]
mask = self.causal_attention_mask(seq_len)
x = self.embedding(token_ids)
for block in self.transformer_blocks:
x = block(x, mask=mask)
return self.output_layer(x)
jnp.tril produces a lower-triangular matrix of ones. Position (i, j) is 1 if j ≤ i, meaning token i is allowed to attend to token j. This single matrix enforces the autoregressive property of the model.
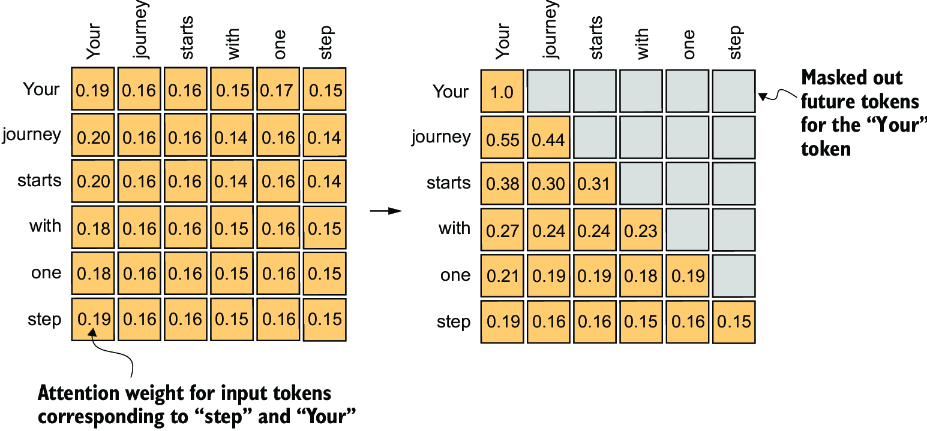
The causal mask — each token (row) can only attend to itself and previous tokens (columns). Future positions are masked out.
Part 3: The Flax NNX Learning Curve
Flax has two APIs: the older linen API and the newer nnx API. This project uses NNX, which is more Pythonic — modules hold their own state rather than requiring external parameter trees.
The gotcha that cost me real time:
Flax 0.11.0 changed the Optimizer and update signatures without much fanfare:
# Flax < 0.11.0
optimizer = nnx.Optimizer(model, optax.adamw(...))
optimizer.update(grads)
# Flax >= 0.11.0 — both arguments now required
optimizer = nnx.Optimizer(model, optax.adamw(...), wrt=nnx.Param)
optimizer.update(model, grads)
The error message (Missing required argument 'wrt') points you in the right direction, but if you’re following a tutorial written before 0.11.0 you’ll hit this immediately. Always check your Flax version against the tutorial’s requirements.
Part 4: Data Loading with Grain
Rather than writing a custom DataLoader, this project uses Google’s grain library — a JAX-native data loading library built for performance.
dataset = StoryDataset(stories, maxlen, tokenizer)
sampler = pygrain.IndexSampler(
num_records=len(dataset),
shuffle=True,
seed=42,
shard_options=pygrain.NoSharding(),
num_epochs=num_epochs,
)
dataloader = pygrain.DataLoader(
data_source=dataset,
sampler=sampler,
operations=[pygrain.Batch(batch_size=batch_size, drop_remainder=True)]
)
Each story is tokenized and right-padded to maxlen=128 with zeros. The target sequence is simply the input shifted one position to the right:
# Input: [Once, upon, a, time, ...]
# Target: [upon, a, time, ..., <pad>]
prep_target_batch = jax.vmap(
lambda tokens: jnp.concatenate((tokens[1:], jnp.array([0])))
)
This is where vmap shines — write the transformation for a single sequence, apply it across the entire batch automatically.
Part 5: Training Loop
The training loop uses nnx.value_and_grad to compute loss and gradients in a single pass:
@nnx.jit
def train_step(model, optimizer, metrics, batch):
input_ids, target_ids = batch
def loss_fn(model):
logits = model(input_ids)
loss = optax.softmax_cross_entropy_with_integer_labels(
logits.reshape(-1, vocab_size),
target_ids.reshape(-1)
).mean()
return loss, logits
(loss, logits), grads = nnx.value_and_grad(loss_fn, has_aux=True)(model)
optimizer.update(model, grads)
metrics.update(loss=loss, logits=logits, labels=target_ids)
The @nnx.jit decorator compiles the entire train step — forward pass, loss computation, gradient calculation, and weight update — into a single XLA kernel. The first call is slow (compilation), every subsequent call is fast.
How @jax.jit works — Python traces your function once, XLA compiles it, then every subsequent call skips Python entirely.
A subtle bug to watch for in the training loop:
# WRONG — step only increments once per epoch
for batch in dataloader:
train_step(...)
step += 1 # ← outside the for loop
# CORRECT — step increments every batch
for batch in dataloader:
train_step(...)
step += 1 # ← inside the for loop
Python indentation bugs are silent and insidious in training loops.
Part 6: Checkpointing with Orbax
Orbax is JAX’s native checkpointing library. Saving and restoring model state:
# Save
checkpointer = orbax.checkpoint.PyTreeCheckpointer()
checkpointer.save(checkpoint_path, nnx.state(model))
# Restore
restored_state = checkpointer.restore(
checkpoint_path,
item=nnx.state(model),
restore_args=restore_args
)
nnx.update(model, restored_state)
nnx.state(model) extracts the parameter pytree from the model. nnx.update(model, restored_state) writes it back in. The model architecture must match exactly — if you change embed_dim from 192 to 256, the checkpoint will fail to load because the weight shapes no longer match.
This also means you can load someone else’s checkpoint on your machine, instantly inheriting their training without running a single training step. This is how the 20M-token checkpoint used in this project was loaded and run on a fresh Colab session.
Part 7: Text Generation
Generation uses greedy decoding (argmax) with temperature scaling:
Autoregressive generation — the model predicts one token at a time, appending each prediction back to the input for the next step.
def generate_text(model, start_tokens, max_new_tokens=50, temperature=1.0):
tokens = list(start_tokens)
for _ in range(max_new_tokens):
context = tokens[-model.maxlen:]
actual_len = len(context)
# Right-pad to maxlen to match training
if actual_len < model.maxlen:
context = context + [0] * (model.maxlen - actual_len)
context_array = jnp.array(context)[None, :]
logits = model(context_array)
# Sample from the position of the LAST real token, not position 0
next_token_logits = logits[0, actual_len - 1, :] / temperature
next_token = int(jnp.argmax(next_token_logits))
if next_token == END_TOKEN_ID:
break
tokens.append(next_token)
return tokenizer.decode(tokens)
The line logits[0, actual_len - 1, :] is easy to get wrong. You want the logits at the position of the last real token — not position 0, and not the last padded position. Getting this wrong results in the model repeating the prompt with no new tokens generated.
Temperature controls how peaked the probability distribution is:
temperature=0.2→ conservative, repetitive outputtemperature=1.0→ balancedtemperature=1.5→ creative, sometimes incoherent
Results
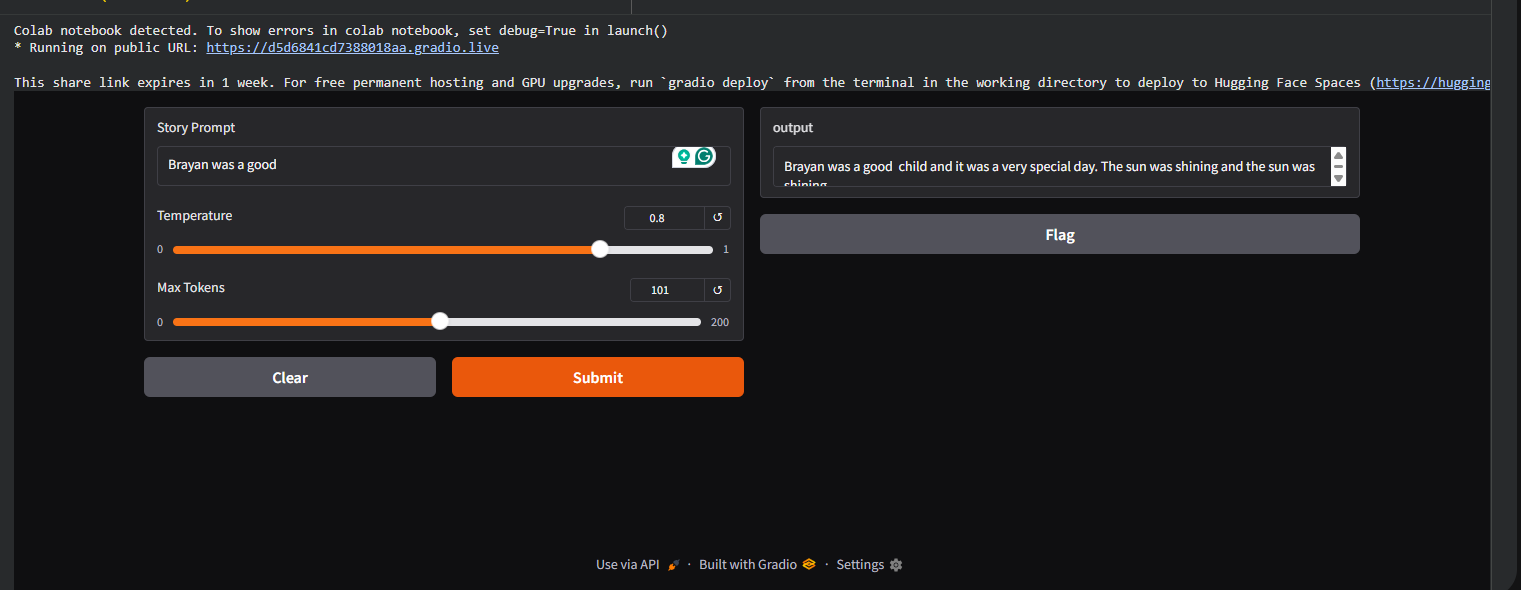
Trained on the TinyStories dataset with a 20M-token checkpoint, the model generates coherent short stories:
Prompt: "Once upon a time a big bear"
Output: "Once upon a time a big bear lived in the forest.
He liked to walk and find berries. One day he
met a little rabbit who was lost..."
The model learned basic story structure, character introduction, and simple cause-and-effect narrative — all from a 6-layer, 192-dimensional transformer.
What’s Next
- Add layer normalisation to the transformer blocks (currently missing)
- Replace greedy decoding with top-k or nucleus sampling for more varied output
- Scale up: larger
embed_dim, more blocks, more training data - Experiment with RoPE positional embeddings instead of learned positions
Try It Yourself
The full code is on GitHub: MinGPT-Implementation-with-Jax
A Colab notebook is included — mount your Drive, run the cells, and you can load the pretrained checkpoint and start generating stories in under a minute.
Built with JAX, Flax NNX, Optax, Orbax, Grain, and tiktoken.