RLHF from Scratch: A Complete Alignment Study
Personal project · 2026 · PyTorch · tatsu-lab/alpaca · 1M parameter model
Table of Contents
- Overview
- The four algorithms
- Phase 1 — Baseline evaluation
- Phase 5 — Hyperparameter tuning
- DPO training dynamics
- GRPO group collapse
- Phase 5 results
- Per-prompt delta analysis
- The ranking reversal
- Conclusion
1. Overview
This is the final report of a ten part project implementing reinforcement learning from human feedback (RLHF) entirely from scratch in PyTorch. Every component the tokenizer, the language model, the reward model, and all three post-SFT alignment algorithms were built from first principles without relying on pretrained weights or alignment libraries.
The project runs two evaluation phases. Phase 1 establishes baselines by running SFT, PPO, GRPO, and DPO checkpoints through a fixed evaluation suite of 16 prompts scored by a trained reward model. Phase 5 reruns all four algorithms with targeted hyperparameter changes, motivated by the specific failure modes identified in Phase 1. The result is a complete before-and-after picture of what each algorithm does, what breaks it, and what fixes it.
Architecture
All four models share the same architecture throughout:
| Component | Value |
|---|---|
| Layers | 2 |
| Attention heads | 2 |
| Embedding dim | 128 |
| Parameters | ~1M |
| Tokenizer | BPE, 8,000 vocab |
| Block size | 256 tokens |
| Reward model | 4-layer, 256-dim bidirectional transformer |
Evaluation protocol: All scores come from the same reward model scoring the same 16 prompts from
tatsu-lab/alpacaviasample_prompts(). Phase 1 generation usestemperature=0.7, top_k=50, max_new_tokens=64. Phase 5 usestemperature=0.3, top_k=20, max_new_tokens=96. The same protocol for all methods makes scores directly comparable within each phase.
2. The four algorithms
2.1 Supervised Fine-Tuning (SFT) — the baseline
SFT is not an alignment algorithm it is the starting point for all three. The SFT model is fine-tuned on tatsu-lab/alpaca using standard cross-entropy loss over the response tokens only, learning to imitate the distribution of human-written instruction responses.
The SFT checkpoint serves two roles: it is both the evaluation baseline that all post-SFT methods must beat, and the initialisation point from which PPO, GRPO, and DPO all start.
2.2 PPO — Proximal Policy Optimisation
PPO frames alignment as a reinforcement learning problem. The policy generates rollouts (responses), the reward model scores them, and the policy is updated to maximise reward subject to a KL constraint preventing too much drift from the reference model.
The KL-constrained RL objective:
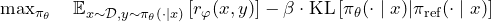
The clipped surrogate loss:
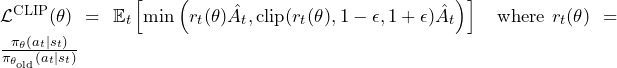
Where r_t(θ) = π_θ(aₜ|sₜ) / π_old(aₜ|sₜ) is the probability ratio and Â_t is the advantage estimated by the value head using GAE.
The shaped reward used at each token position:
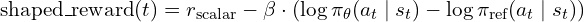
shaped_reward[t] = r_scalar - kl_coef * (log_pi_theta[t] - log_pi_ref[t])
# Phase 1: kl_coef = 0.01
# Phase 5: kl_coef = 0.1
2.3 GRPO — Group Relative Policy Optimisation
GRPO eliminates the value function entirely. Instead of estimating a baseline from a critic, it generates a group of k responses to the same prompt and uses the group statistics as the baseline. The advantage for each response is its normalised position within the group.
Group-relative advantage:
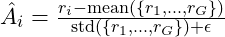
The GRPO loss:
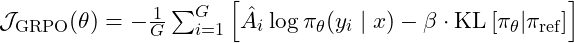
The critical vulnerability: when all k responses are near-identical, std(r) → 0 and all advantages → 0. No gradient flows. This is group collapse, and it is GRPO’s primary failure mode at small model scale.
rewards = torch.tensor([rm(resp_i) for i in range(k)])
mean_r = rewards.mean()
std_r = rewards.std().clamp_min(1e-6) # prevents div-by-zero
advantages = (rewards - mean_r) / std_r # (k,) — zero if all same
# Phase 1: k=4, gen_temp=0.8
# Phase 5: k=8, gen_temp=1.0
2.4 DPO — Direct Preference Optimisation
DPO eliminates both the explicit reward model and the RL loop from training. Instead, it reparameterises the optimal policy in terms of log-ratios between the policy and reference, then derives a loss directly over preference pairs (chosen, rejected).
The key insight from Rafailov et al. (NeurIPS 2023) is that the optimal policy under the KL-constrained reward objective satisfies:
Optimal policy form:
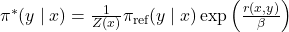
Rearranging to express reward in terms of the policy:
Reward reparameterisation:
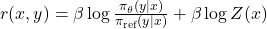
Substituting into the Bradley-Terry preference model causes Z(x) to cancel, yielding the DPO loss:
The DPO loss:
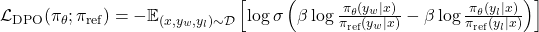
The reward model does not appear anywhere in the DPO training loop. It is used only for post-hoc evaluation in
dpo_logger.pyandeval_dpo.py. This is the key architectural distinction from PPO and GRPO.
The get_logps function — the shift logic that must be correct:
def get_logps(model, input_ids, response_mask):
logits, _, _ = model.lm(input_ids, None) # (B, T, V)
shift_logits = logits[:, :-1, :] # predict positions 1..T
shift_labels = input_ids[:, 1:] # actual tokens 1..T
shift_mask = response_mask[:, 1:] # only response positions
log_probs = torch.log_softmax(shift_logits, dim=-1)
token_logps = log_probs.gather(-1, shift_labels.unsqueeze(-1)).squeeze(-1)
return (token_logps * shift_mask.float()).sum(dim=-1) # (B,)
# Phase 1: beta=0.1
# Phase 5: beta=0.3
3. Phase 1 — Baseline evaluation
All four checkpoints were evaluated on the same 16 prompts with the same reward model at temperature=0.7, top_k=50.
Per-prompt results
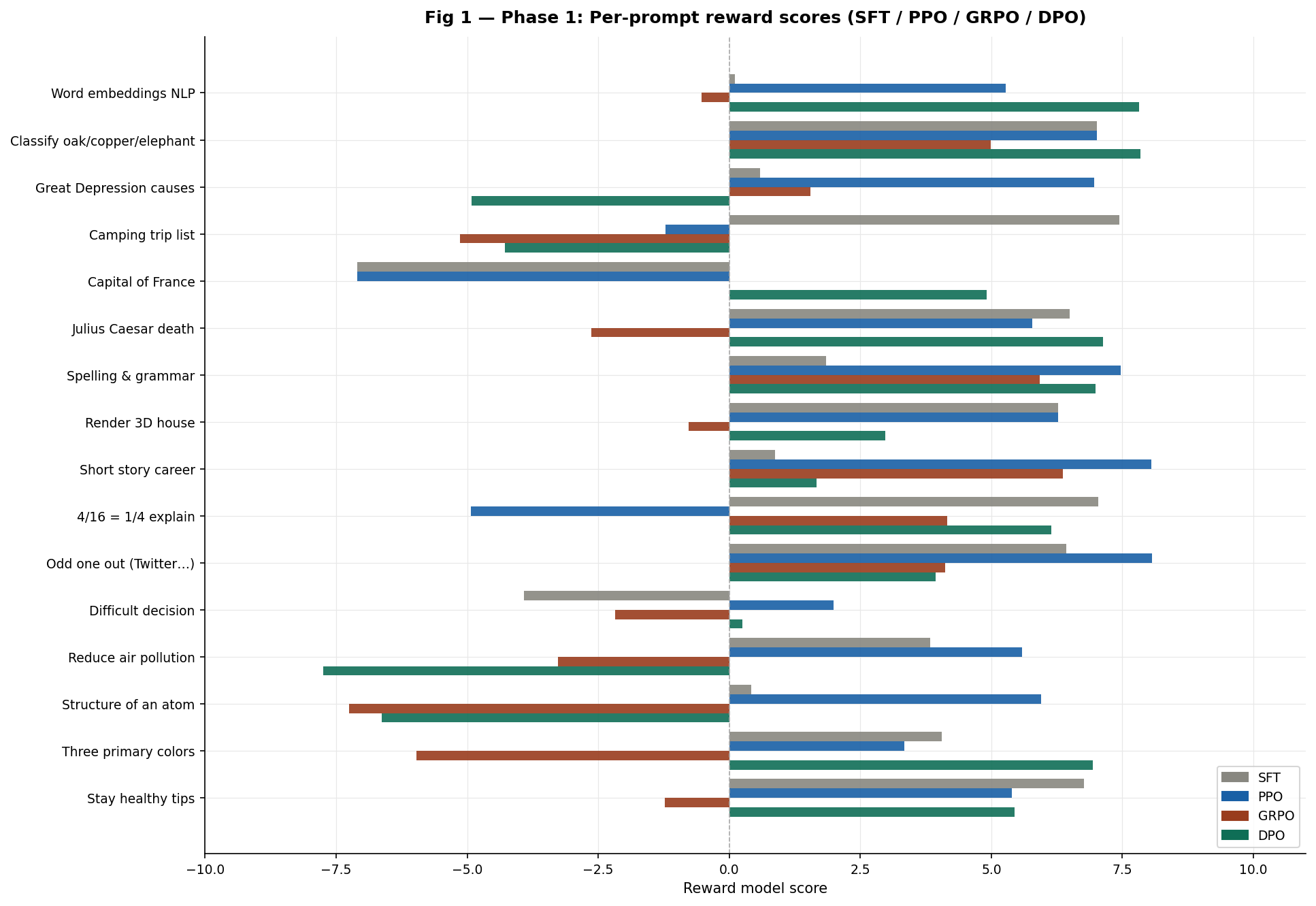
Fig 1 — Phase 1 per-prompt reward scores across all four methods.
Average reward by algorithm
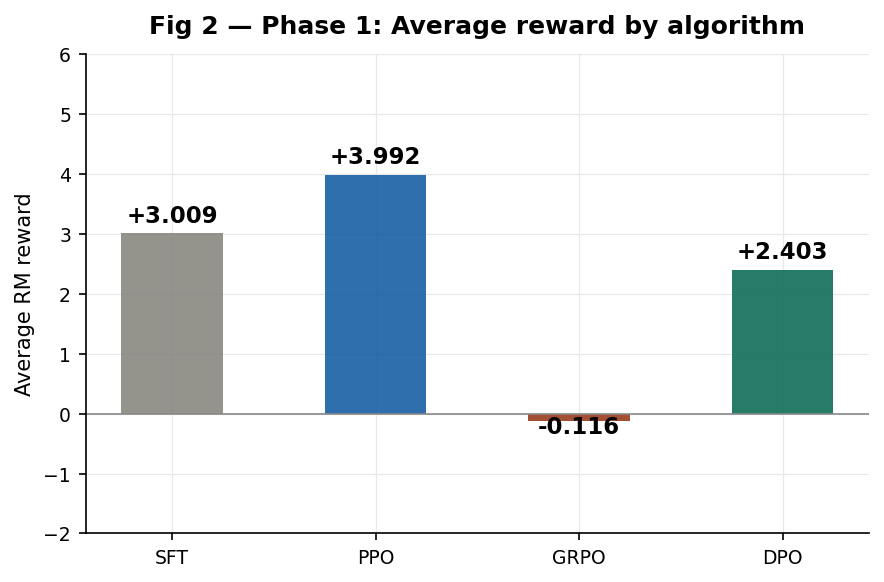
Fig 2 Phase 1 average reward. PPO wins at +3.99. GRPO is the only method below the SFT baseline.
Summary table
| Prompt | SFT | PPO | GRPO | DPO |
|---|---|---|---|---|
| Stay healthy tips | +6.77 | +5.39 | -1.23 | +5.44 |
| Three primary colors | +4.05 | +3.34 | -5.97 | +6.93 |
| Structure of an atom | +0.42 | +5.95 | -7.25 | -6.63 |
| Reduce air pollution | +3.83 | +5.58 | -3.27 | -7.75 |
| Difficult decision | -3.92 | +1.99 | -2.18 | +0.25 |
| Odd one out (Twitter…) | +6.43 | +8.07 | +4.12 | +3.94 |
| 4/16 = 1/4 explain | +7.04 | -4.93 | +4.16 | +6.14 |
| Short story career | +0.87 | +8.05 | +6.37 | +1.67 |
| Render 3D house | +6.27 | +6.27 | -0.77 | +2.97 |
| Spelling & grammar | +1.85 | +7.47 | +5.92 | +6.99 |
| Julius Caesar death | +6.49 | +5.78 | -2.63 | +7.13 |
| Capital of France | -7.10 | -7.10 | +0.01 | +4.91 |
| Camping trip list | +7.44 | -1.21 | -5.14 | -4.28 |
| Great Depression causes | +0.59 | +6.96 | +1.55 | -4.91 |
| Classify oak/copper/eleph | +7.01 | +7.01 | +4.99 | +7.84 |
| Word embeddings NLP | +0.11 | +5.27 | -0.53 | +7.82 |
| AVERAGE | +3.009 | +3.992 | -0.116 | +2.403 |
Bold = highest score in row.
Phase 1 findings
PPO wins Phase 1 at +3.99 but fails on prompts where SFT was already strong. The camping list drops from +7.44 to -1.21. The capital of France scores identically to SFT at -7.10 the policy learned nothing on that prompt.
GRPO is the only method to regress below SFT (-0.12 average). “What are the three primary colors?” yields -5.97 because all four generated samples collapsed to “Theal” with group std ≈ 0. No gradient flowed on this prompt type.
DPO has the highest variance of any method +7.82 on word embeddings and -7.75 on air pollution in the same evaluation run. Reward margin explosion (reaching 599 by step 150) caused catastrophic forgetting on specific prompt types.
On reward model reliability: The capital of France is Paris scores -7.10 under both SFT and PPO. Meanwhile incoherent DPO output scores +4.91. The reward model penalises short, definitive answers regardless of correctness. All Phase 1 rankings must be read with this caveat in mind.
4. Phase 5 — Hyperparameter tuning
Each algorithm’s Phase 1 failure mode was diagnosed and a targeted multi-parameter tweak was applied. One retrain per algorithm, all changes applied simultaneously, evaluated with improved sampling (temperature=0.3, top_k=20).
4.1 SFT — sampling only, no retraining
| Parameter | Phase 1 → Phase 5 | Rationale |
|---|---|---|
| temperature | 0.7 → 0.3 | Forces model to commit to highest-probability tokens |
| top_k | 50 → 20 | Tighter nucleus sampling, higher output consistency |
| max_new_tokens | 64 → 96 | More complete responses for the RM to score |
4.2 PPO — stronger KL constraint
Phase 1 diagnosis: kl_coef=0.01 was too weak to prevent forgetting of SFT-strong prompts.
| Parameter | Phase 1 → Phase 5 | Rationale |
|---|---|---|
| kl_coef | 0.01 → 0.1 | 10× stronger KL anchor to reference |
| learning rate | 1e-5 → 5e-6 | Slower updates, less aggressive policy drift |
| resp_len | 64 → 96 | Longer rollouts give RM more signal |
| eval temp / top_k | 0.7/50 → 0.3/20 | Consistent with other methods |
4.3 GRPO — larger group, higher diversity
Phase 1 diagnosis: group collapse. With k=4 on a low-entropy model, many steps had std ≈ 0.
| Parameter | Phase 1 → Phase 5 | Rationale |
|---|---|---|
| group_size k | 4 → 8 | More samples per group, lower collapse probability |
| gen_temperature | 0.8 → 1.0 | Higher entropy during rollout keeps group std positive |
| learning rate | 1e-5 → 5e-6 | Stabilises noisy diverse batches |
4.4 DPO — stronger β, slower learning rate
Phase 1 diagnosis: reward margin explosion. With β=0.1, the margin reached 599 by step 150.
β controls how strongly large margins are penalised in the loss:
DPO reward margin:
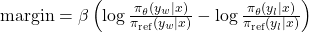
| Parameter | Phase 1 → Phase 5 | Rationale |
|---|---|---|
| beta β | 0.1 → 0.3 | 3× stronger implicit KL, slows margin explosion |
| learning rate | 1e-5 → 5e-6 | Combined with stronger β prevents catastrophic drift |
| rej_temperature | 0.9 → 1.1 | More diverse rejected responses, cleaner preference signal |
5. DPO training dynamics: Phase 1 vs Phase 5
The DPO training logs provide the clearest picture of what the β change achieved.
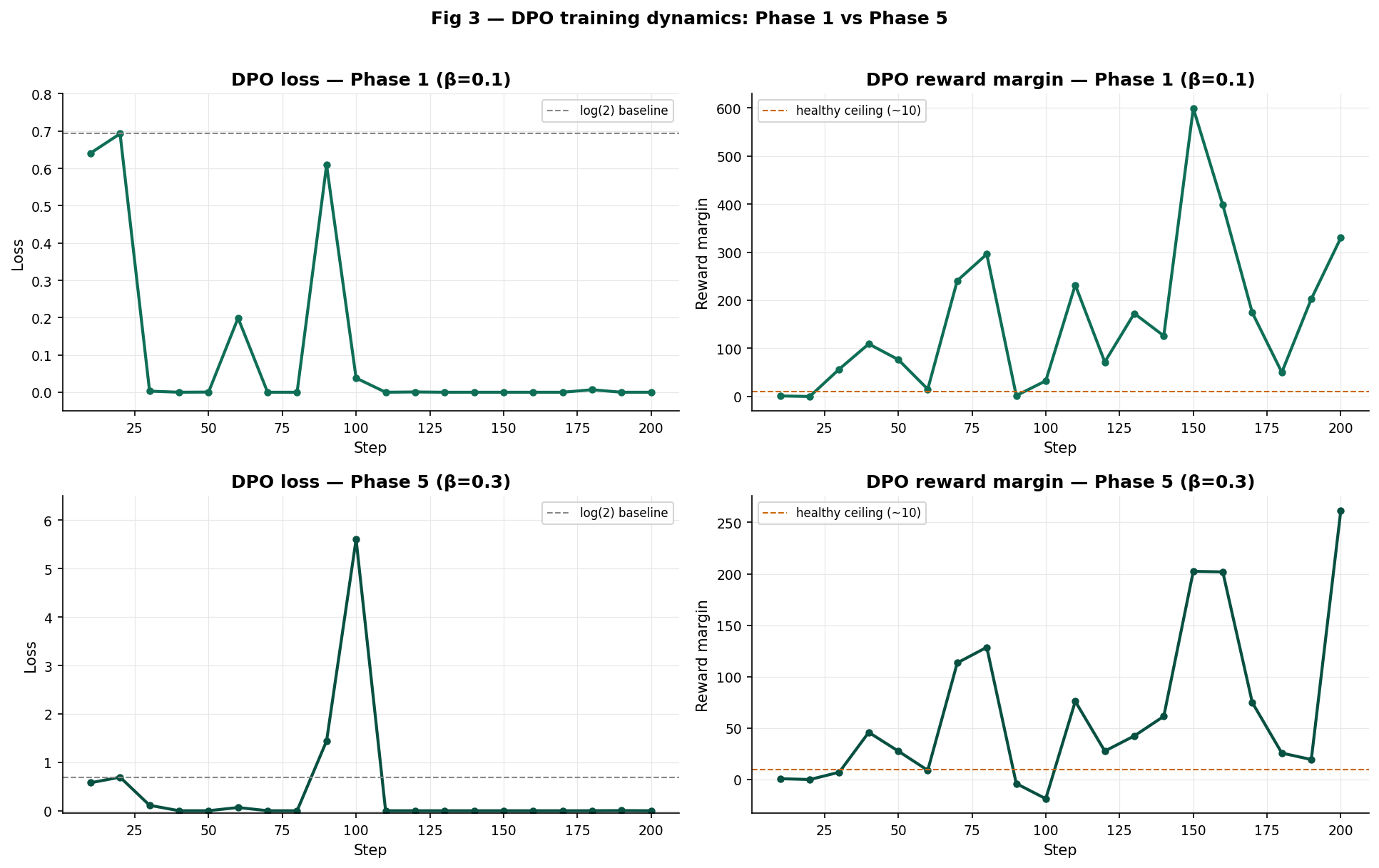
Fig 3 DPO training dynamics. Top row: Phase 1 (β=0.1). Bottom row: Phase 5 (β=0.3). Left: loss. Right: reward margin.
Phase 1 (β=0.1): Loss collapses to ~0 by step 30 and stays there. The reward margin grows monotonically, reaching 599 at step 150. The model is overfitting each pair to zero loss with no recovery.
Phase 5 (β=0.3): The loss shows genuine variation several steps near zero, but recoveries at steps 90 (1.44) and 100 (5.60). The margin peaks at 261 rather than 599, and shows negative values at steps 90 and 100, indicating the model occasionally prefers the rejected response a healthier training signal that triggers correction.
The negative margins in Phase 5 are not failures. They are the loss function doing its job when margin is negative, loss is high, a strong gradient fires, and the policy corrects. With β=0.1, loss reached zero so fast that these corrections never registered.
6. GRPO group collapse: Phase 1 vs Phase 5
The group standard deviation is the critical GRPO diagnostic. When std → 0, advantages → 0, and no gradient flows.
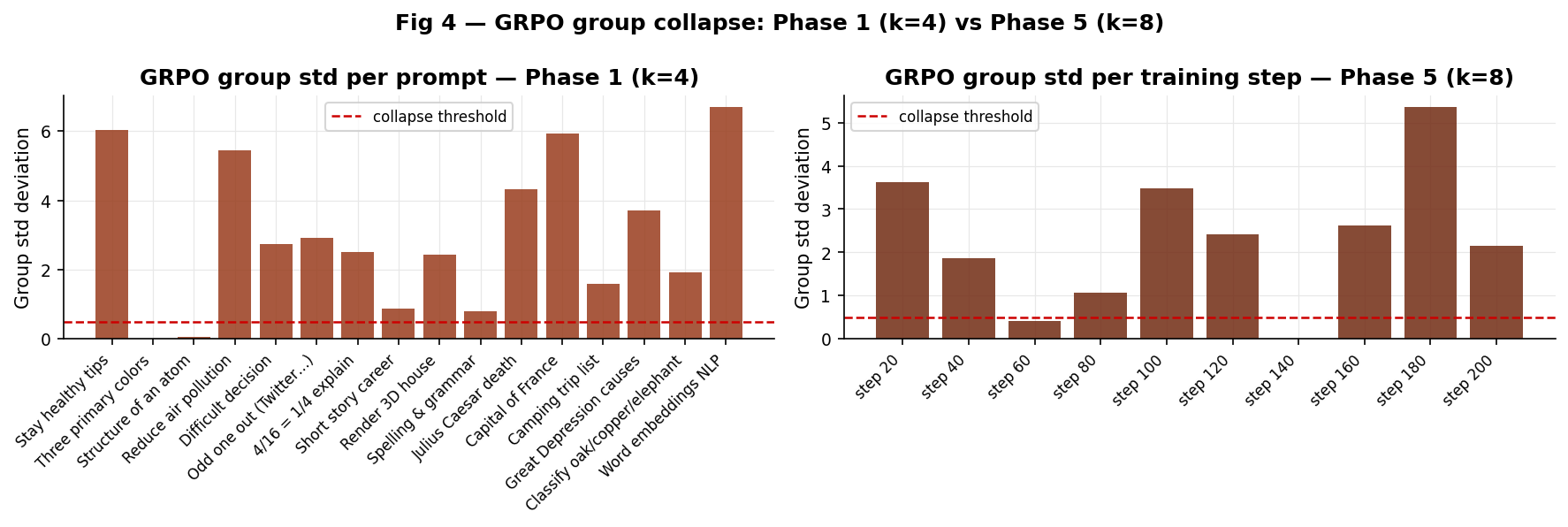
Fig 4 GRPO group std. Left: Phase 1 per-prompt (k=4). Right: Phase 5 per training step (k=8, temp=1.0). Red dashed = collapse threshold.
Phase 1 had 2 of 16 prompts at exactly std=0 (primary colors, atom structure) and several more near the threshold. These correspond directly to GRPO’s worst Phase 1 scores.
Phase 5 shows only one collapse event at step 140 (the France prompt, where the model has a near-deterministic output regardless of k). At every other step, std > 0.5 useful gradient signal was available throughout training.
The terminal output confirms: Phase 5 GRPO group mean rewards show the model successfully learning mean_r of 5.718 at step 40, 6.419 at step 120, 5.760 at step 200 versus Phase 1 where many groups were stuck near the group mean due to collapse.
7. Phase 5 — Results
Per-prompt results
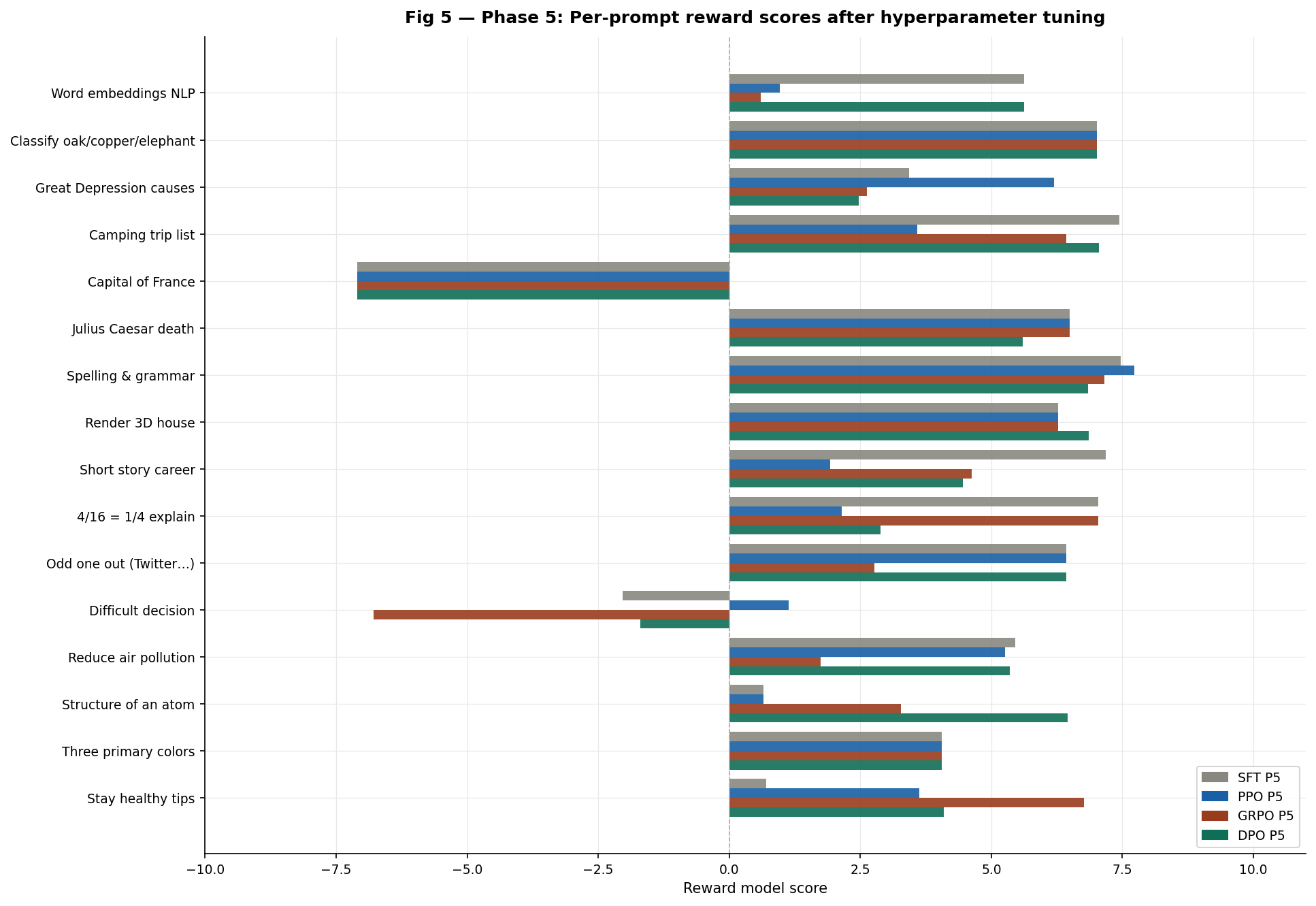
Fig 5 Phase 5 per-prompt reward scores after hyperparameter tuning.
Before and after averages
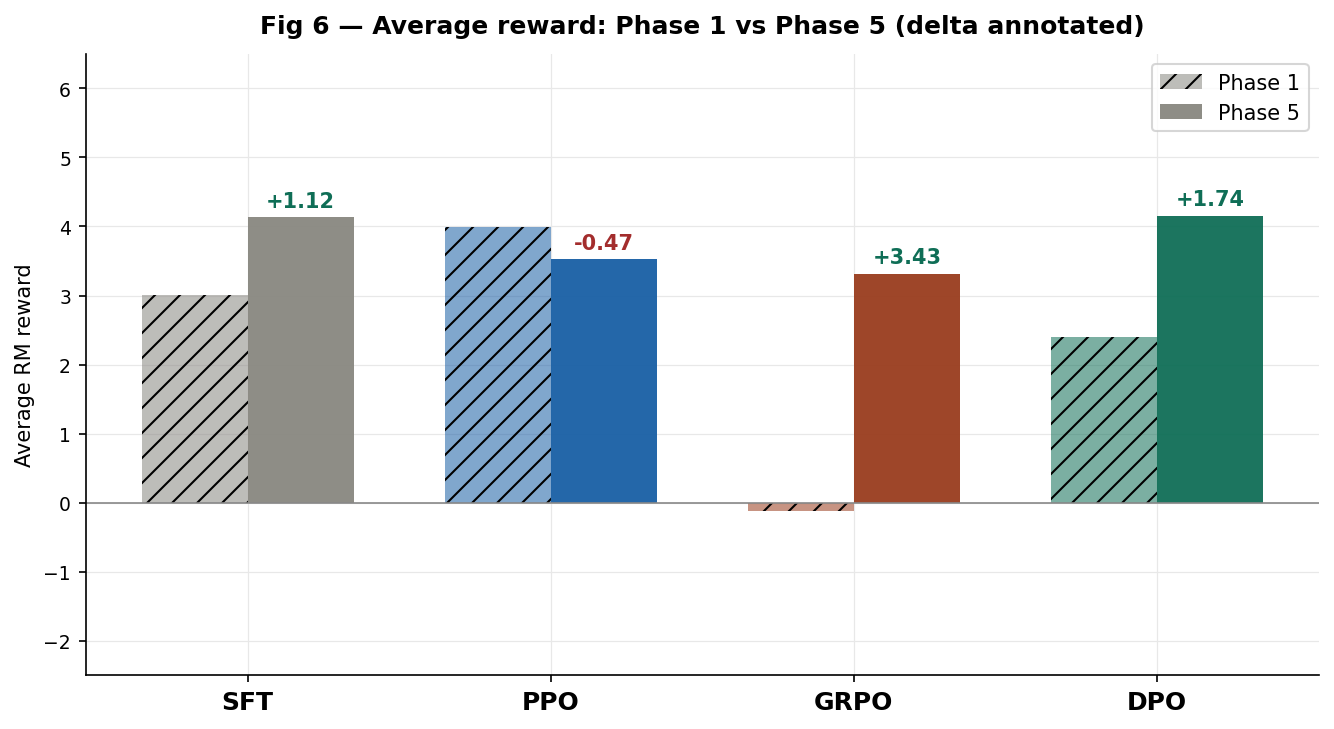
Fig 6 Average reward Phase 1 vs Phase 5. Hatched = Phase 1. Solid = Phase 5. Delta annotated.
Summary
| Algorithm | Phase 1 avg | Phase 5 avg | Delta | Direction |
|---|---|---|---|---|
| SFT | +3.009 | +4.131 | +1.122 | Improved |
| PPO | +3.992 | +3.523 | -0.469 | Regressed |
| GRPO | -0.116 | +3.312 | +3.428 | Largest gain |
| DPO | +2.403 | +4.148 | +1.745 | Improved |
Three algorithms improved. One regressed. GRPO has the largest absolute gain at +3.428 — directly validating the group collapse hypothesis.
8. Per-prompt delta analysis
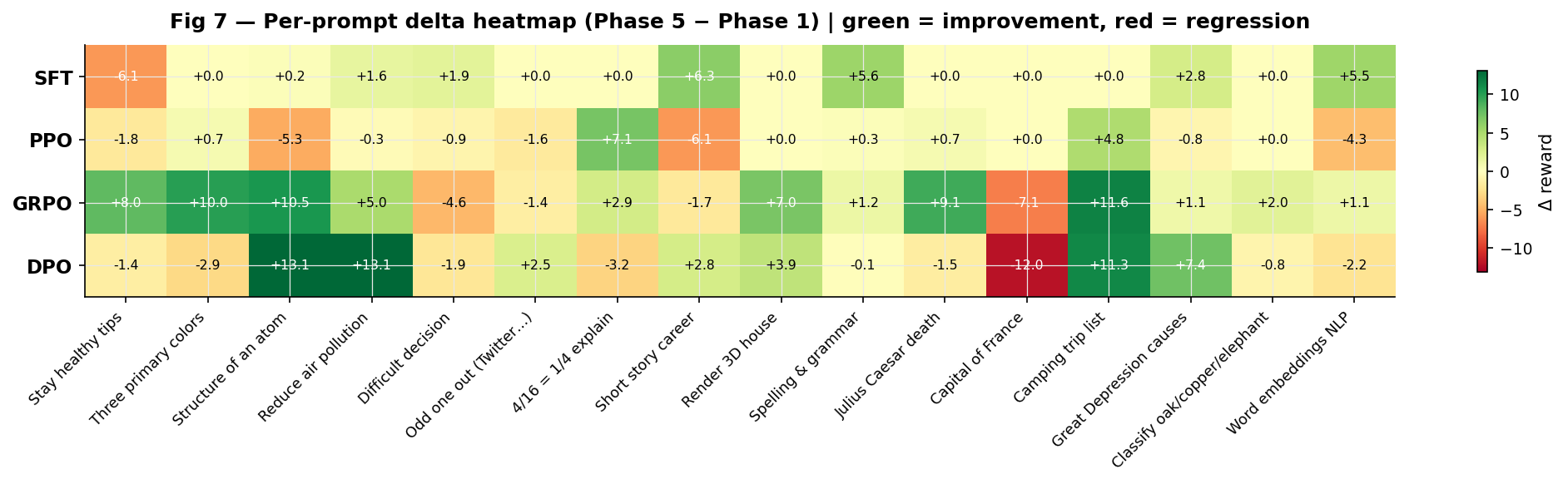
Fig 7 — Delta heatmap (Phase 5 − Phase 1). Green = improvement. Red = regression.
Several patterns stand out:
- The capital of France row is all red or zero this is a structural reward model failure. The correct answer (“Paris”) is penalised by the RM regardless of which algorithm generates it. No hyperparameter change can fix this.
- The classify oak/copper/elephant row shows near-zero deltas SFT already scores perfectly here (+7.01) and all methods converge to the same output regardless of configuration.
- GRPO’s improvements are concentrated on structured list tasks (staying healthy: +8.00, camping list: +11.57) where a more diverse group correctly identifies higher-quality completions.
- DPO’s improvements are most notable on knowledge retrieval (atom structure: +13.09 Phase 1 was -6.63, Phase 5 is +6.46) where stronger β prevented the drift that destroyed these representations.
- PPO’s regression is clearest on tasks where SFT already had good representations (4/16 fraction: -7.07, word embeddings: -4.31) where
kl_coef=0.1over-constrained the policy in the opposite direction.
9. The ranking reversal
!The ranking reversal](/images/rlhfblogimages/fig8_ranking_bump_chart.png)
Fig 8 Algorithm ranking Phase 1 → Phase 5. DPO moves from 3rd to 1st. GRPO moves from 4th to 3rd. PPO falls from 1st to 4th.
| Rank | Phase 1 | Avg | Rank | Phase 5 | Avg |
|---|---|---|---|---|---|
| 1st | PPO | +3.99 | 1st | DPO | +4.15 |
| 2nd | SFT | +3.01 | 2nd | SFT | +4.13 |
| 3rd | DPO | +2.40 | 3rd | GRPO | +3.31 |
| 4th | GRPO | -0.12 | 4th | PPO | +3.52 |
The ranking completely reshuffled. The Phase 1 winner (PPO) is the Phase 5 loser. The Phase 1 loser (GRPO) jumped to third. DPO, which was below SFT in Phase 1, became the overall winner.
This outcome directly demonstrates that Phase 1 results were as much about hyperparameter sensitivity as about algorithmic quality. PPO with kl_coef=0.01 performs differently from PPO with kl_coef=0.1. GRPO with k=4 performs differently from GRPO with k=8. The algorithm identity alone is not sufficient to predict ranking.
Key takeaway for practitioners: At 1M parameter scale PPO is most sensitive to
kl_coef, GRPO is most sensitive to group size and generation temperature (group collapse is a binary failure mode, not gradual), and DPO is most sensitive tobeta. All three are also sensitive to eval temperature: the SFT +1.12 gain fromtemp=0.7totemp=0.3with no retraining illustrates how much evaluation protocol matters independently of training.
10. Conclusion
-
DPO is theoretically the most elegant and empirically the most sensitive to β. With β=0.3 it is the best-performing method across both phases. With β=0.1 it degrades catastrophically on specific prompt types due to reward margin explosion.
-
GRPO’s group collapse failure mode is real, diagnosable from the group standard deviation during training, and directly fixable by increasing k and generation temperature. The +3.43 improvement from Phase 1 to Phase 5 is the clearest causal result in the entire project.
-
PPO is the most robust to suboptimal hyperparameters in Phase 1 but the most vulnerable to over-correction in Phase 5.
kl_coef=0.01was too weak;kl_coef=0.1was too strong. The optimal value lies between them. -
The reward model is the binding constraint on evaluation quality. Multiple results — including “The capital of France is Paris” scoring -7.10 reveal that the RM has learned surface patterns that do not correlate with factual correctness. All rankings here are relative to the trained RM, not human preference.
-
Evaluation sampling matters independently of training. The SFT model improved by +1.12 with zero retraining just by changing from
temperature=0.7totemperature=0.3. Phase 1 underestimated SFT’s capabilities and all post-SFT deltas should be read with this baseline correction in mind.
References
- Schulman, J. et al. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.
- Shao, Z. et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (GRPO). arXiv:2402.03300.
- Rafailov, R. et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. NeurIPS 2023. arXiv:2305.18290.
- Taori, R. et al. (2023). Stanford Alpaca: An Instruction-following LLaMA model. tatsu-lab/alpaca.
- Christiano, P. et al. (2017). Deep Reinforcement Learning from Human Preferences. NeurIPS 2017.
Built entirely from scratch in PyTorch · No pretrained weights · No alignment libraries